This list is not exhaustive. Instead, it is a selection of object storage implementations and details that appear interesting.
Some themes that it many or all of these comparators struggled with include:
-
New systems to meet scaling needs Facebook, Google, and Yahoo are all very open about having reinvented their object storage solutions to address evolving needs (typically cost and availability) as they scaled. Those players dramatically reinvented their systems without strong regard for backwards compatibility, but evidence suggests S3 has gone through similarly dramatic changes as well, but without breaking API compatibility. Interestingly, Ceph has also gone through generational improvements, but these have been possible within storage plugins without changing the public interfaces.
-
Reduction of cost per unit of storage A key priority for most storage solutions has been to reduce the cost per unit of storage while meeting increasing availability goals. This goal is what drove the need to create next-generations systems in the past decade at Facebook, Google, and Yahoo (and probably others). Where details are available, all those systems switched from a replication model to an erasure coded storage model to meet those goals.
-
Filesystem complexity As noted in the Haystack paper, one of the most important goals of object storage is to eliminate the overhead of filesystems, but that same goal was turned inward, and it appears more recent object storage solutions have eliminated the filesystem from the storage hosts. This can be seen in Ceph and is hinted at for Google’s architecture.
Entries are ordered alphabetically. Jump to any section:
AlibabaCloud Object Storage Service
Relatively little is known about AlibabaCloud’s OSS, but the pricing compares favorably against S3. The product description claims to store three copies of every object, though I can find no architectural details.
Though AlibabaCloud (also called AliCloud and AliyunCloud) OSS uses different API than S3, the company has been careful to copy the usage and semantics of the S3 API (and the APIs of all AWS services). Compare the Terraform configuration instructions for AliCloud and AWS, for example (I cannot find the source now, but I recall reading that some AWS SDKs could be used against AliCloud just by changing the endpoint). This table appears to show all the differences between OSS and and S3 as of 2016.
Azure Blob Storage
Azure Blob Storage (ABS) is Microsoft’s direct answer to S3. To differentiate itself, their marketing highlights strong consistency, object mutability, multiple blob types, and automated geo-redundancy as features that S3 users might not expect. This table maps Azure’s terminology to AWS’:
| Azure Blob Storage | AWS S3 |
|---|---|
| Container | Bucket |
| Blob | Object |
| Hot | S3 Standard |
| Cool | S3 Infrequent Access (IA) |
| Archive | AWS Glacier |
The service supports three types of blobs: block blobs, page blobs, and append blobs. “Append blobs are similar to block blobs in that they are made up of blocks, but they are optimized for append operations, so they are useful for logging scenarios.”
The durability and availability options for Azure Blob Storage range in claimed durability from 11 to 16 nines. The least of those (LRS) is replicated within a single data center for 11 nines, but replication among multiple data centers in a single region (ZRS) gains an extra nine, while replicating to different regions (GRS and RA-GRS) yields 16 nines.
As with AWS S3, ABS supports three tiers of access, called “hot,” “cool,” and “archive.” The biggest differences between the tiers are cost and latency of access (storage costs go down as transaction costs and latency go up). Though the storage tier was previously set per storage account (each Azure account can have multiple storage accounts), the service now allows the access tier to be set per object.
More interestingly, ABS supports locking and multiple concurrency models that S3 does not: optimistic, pessimistic, and last write wins. Strong consistency was a key marketing point at the time of the product’s introduction.
Implementation details of ABS are especially scarce, but Azure has published some performance targets for storage:
- Maximum request rate per storage account (a single Azure account can have multiple storage accounts, many customers use one storage account per project/application)
- 20,000 requests per second, though users can request increases
- Max ingress per storage account (US Regions)
- 20 Gbps for LRS
- Max egress per storage account (US Regions)
- 30 Gbps for LRS
- Target throughput for single blob
- Up to 60 MiB per second, or up to 500 requests per second
Though ABS is highly ranked by Gartner and Microsoft has worked hard to provide features that differentiated the service from S3, the company was forced in 2016 to acknowledge S3 API compatibility was a requirement (though they implemented that via a proxy customers had to run themselves). Similarly, a common use for Minio is as an S3 to Azure gateway, and there’s at least one commercial gateway in this space.
Ceph
Ceph is an open source hybrid storage solution that natively supports S3 interactions (in addition to block and NFS). The architecture separates the storage layer from the consumer interfaces, which could make it easier to implement more interfaces as needed.
The Ceph S3 tests are widely regarded as the standard for testing S3 clones, and the S3 personality even supports S3-specific features like bucket policies.
Ceph’s object storage architecture supports serving hot objects from cache and bucket resharding, but the metadata tier is somewhat famously economical (small…possibly underimplemented). Many Ceph clusters run with a single metadata server and a hot spare, though multiple MDS are supported.
Each object storage daemon (OSD) manages one or more storage pools. Typically, each OSD manages just one pool, and that pool represents a single physical disk1. That results in multiple OSDs running on each physical node, one per disk in the node. The default method of durability is to replicate objects to multiple OSDs, but Ceph supports a plugin architecture and plugins that provide for erasure coded storage. Erasure coding is specifically recommended to increase storage efficiency while maintaining object durability.
Object integrity is maintained with regular scrubbing, and it has automated recovery of failed storage daemons/disks/nodes (another example) that can be used both to recover from failures and evacuate hardware for replacement.
The elimination of host filesystems and use of raw storage devices for object storage in Ceph is a response to complexity and failures that emerged from managing file systems at scale, and reporting filesystem health up through the application. One example of those difficulties and the risks they create can be seen in the well-known SATApocalypse story, though the frustration of filesystem management and the issues caused by it appear regularly in the literature for cited here, regardless of system.
2015 seems to have been a good year for Ceph performance papers and presentations:
- Current Status of the Ceph Based Storage Systems at the RACF (RACF is the computing facility for the Relativistic Heavy Ion Collider (RHIC) at BNL, the US-based collaborators in the ATLAS experiment at the Large Hadron Collider at CERN, the collaborators in the Large Synoptic Survey Telescope project, and other experiments around the world)
- Ceph ~30PB Test Report from CERN IT-DSS
- Your 1st Ceph cluster Rules of thumb and magic numbers by Mirantis (also see the hardware recommendations)
There are also some well-documented Ceph failures. The Faithlife SATApocalypse and the LMU Student Council Ceph meltdown are two well-known examples. Both failures demonstrated:
- the risks associated with storage management, especially when operators have other responsibilities;
- the greater risks and performance requirements associated with block storage (as opposed to object storage);
- and the challenges of coordinating host file systems with a distributed application (see above).
Additionally, the Faithlife example demonstrated the requirement that the storage software be able to throttle rebuild activity (one of the features the Yahoo team added), and the LMU example demonstrated the importance good operational hygiene, including staging and canary deployments.
DigitalOcean Spaces
DigitalOcean Spaces is the cloud provider’s S3-compatible object storage offering. The documentation touts the S3 compatibility, and they actively recommend customers use the AWS S3 SDKs to interact with the offering. The product was GA’d in 2017.
DreamHost DreamObjects
DreamObjects is DreamHost’s object storage solution, which the company proudly claims is powered by Ceph. The service offers an S3-compatible API to manage objects and closely maps to S3 conventions and semantics.
Erasure coding in object storage
Most of the comparators in this section use some form of erasure coding. In Getting the Most out of Erasure Codes, presented at the 2013 SNIA Storage Developer Conference, Jason Resch of Cleversafe introduces a formula for availability (not durability, but availability implies durability) that estimates the annual downtime and availability of some common storage schemes:
| System/Scheme | Estimated availability | Estimated annual downtime |
|---|---|---|
| RAID 5 across 4 nodes2: | 99.999% (5 nines) | 31.51 minutes |
| Triple replication | 99.9999999% (9 nines) | 31.56 milliseconds |
| 10-of-15 erasure code2 | 99.999999999999% (14 nines)3 | 1.577 nanoseconds |
The author goes on to explain the storage efficiencies of erasure codes:
Unlike replication, erasure codes can increase reliability without increasing storage costs. 2-of-3, 4-of-6, 10-of-15, 20-of-30, etc., all have the same storage overhead of 1.5x [the original object size], but have vastly different fault tolerances.
If we repeat the table above with the total storage required to achieve the estimated availability, the availability improvements are even more remarkable compared to the reduced storage overhead:
| System/Scheme | Total storage required | Estimated availability |
|---|---|---|
| RAID 5 across 4 nodes | 1.25× object size | 99.999% (5 nines) |
| Triple replication | 3× object size | 99.9999999% (9 nines) |
| 10-of-15 erasure code | 1.5× object size | 99.999999999999% (14 nines) |
That is, complete replication of data across three nodes requires substantially more storage overhead, but offers substantially less availability than an erasure coded system across 15 nodes. Said yet another way: you pay a lot more, but get a lot less with object replication (in defense of replication, it can offer greater storage performance).
The paper goes on to discuss CPU costs, rebuild time, and other factors in EC systems, as well as exploring means to optimize them. The author continued his work on an SNIA SDC paper titled New Hashing Algorithms for Data Storage and is said to be co-authoring a book titled Exabyte Data Preservation, Postponing the Inevitable with a collaborator at the UC Storage Systems Research Center (the research papers there are also worth reading).
It is my understanding that S3 and other major cloud storage solutions use some form of erasure coding to achieve the levels of availability they offer at the price points they’re offering it at.
Google Cloud Storage
This section is a incomplete, but I can recommend two papers worth reading:
Haystack and f4
Facebook’s early photo storage solution was on pools of NFS servers, and some of the most important problems to solve were directly related to the performance challenges of that architecture (which, in 2009, was still common for many storage users).
Wikipedia reports from a number of sources: “In April 2009, Haystack was managing 60 billion photos and 1.5 petabytes of storage, adding 220 million photos and 25 terabytes a week. Facebook [in 2013] stated that they were adding 350 million photos a day and were storing 240 billion photos. This could equal as much as 357 petabytes.”
The Haystack paper from 2010 describes the application and its three major components: the Haystack Store, Haystack Directory, and Haystack Cache. The system described in that paper uses object replication for durability, though that has since been replaced with erasure coding (see below).
The architecture assumes objects will rarely be deleted once they are uploaded4, and is designed for constant expansion:
When we increase the capacity of the Store by adding new machines, those machines are write-enabled; only write-enabled machines receive uploads. Over time the available capacity on these machines decreases. When a machine exhausts its capacity, we mark it as read-only.
It appears that architecture is a strong match for their usage pattern, as they make no mention of rebalancing storage. Their usage patterns also indicated a need for caching:
We use the Cache to shelter write-enabled Store machines from reads because of two interesting properties: photos are most heavily accessed soon after they are uploaded and filesystems for our workload generally perform better when doing either reads or writes but not both. Thus the write-enabled Store machines would see the most reads if it were not for the Cache.
The paper describes a compaction process that reclaims storage after photos are deleted or replaced. Storage in Haystack is copy-on-write, so the compaction process is required to garbage collect old duplicates of edited or updated objects. Tooling can rebuild storage nodes from replicas as needed, though the paper identifies this as an area of active improvement at the time.
A 2014 paper described f4, Facebook’s updated object storage solution and reveals “as of February 2014, Facebook stored over 400 billion photos.” Rather than object replication as used in Haystack, f4 uses a combination of Reed-Solomon and XOR coding for durability and availability:
It uses Reed-Solomon coding and lays blocks out on different racks to ensure resilience to disk, machine, and rack failures within a single datacenter. Is uses XOR coding in the wide-area to ensure resilience to datacenter failures. f4 has been running in production at Facebook for over 19 months. f4 currently stores over 65PB of logical data and saves over 53PB of storage.
The paper reports that at the time of publication, they had settled on a n = 10 and k = 4 Reed-Solomon(n, k) code that allowed objects to survive up to four failures without loss of data or availability, while requiring just 1.4× the original object size for that durability (1MB object requires 1.4MB of total storage). More recent stories from Facebook folks suggest they’re now using more sophisticated erasure coding for even higher efficiencies.
Availability and durability are then further increased with geographic distribution in another region:
Geo-replicated XOR coding provides datacenter fault tolerance by storing the XOR of blocks from two different volumes primarily stored in two different datacenters in a third datacenter. Each data and parity block in a volume is XORed with the equivalent data or parity block in the other volume, called its buddy block, to create their XOR block.
The resulting storage requires 2.1× the original object size, but can survive significant disruptions without loss of availability or durability. Though not described in the f4 paper, this storage scheme provides for greater levels of availability and durability than can be achieved in S3 in a single region (though S3 customers can pay for multi-region storage).
The paper outlines four types of failures the authors designed for:
- Drive failures, at a low single digit annual rate.
- Host failures, periodically.
- Rack failures, multiple time per year.
- Datacenter failures, extremely rare and usually transient, but potentially more disastrous.
Those failure types have been tested. In one example the authors offered, we learn that the average failure rate for disks jumped from about 1% to “over 60% for a period of weeks. Fortunately, the high-failure-rate disks were constrained to a single cell and there was no data loss.”
Though the original Haystack required manual rebuilding after failures, f4 appears to have completely automated failure recovery:
At large scale, disk and node failures are inevitable. When this happens blocks stored on the failed components need to be rebuilt. Rebuilder nodes are storage-less, CPU-heavy nodes that handle failure detection and background reconstruction of data blocks. Each rebuilder node detects failure through probing and reports the failure to a coordinator node. It rebuilds blocks by fetching n companion or parity blocks from the failed block’s strip and decoding them. Rebuilding is a heavyweight process that imposes significant I/O and network load on the storage nodes. Rebuilder nodes throttle themselves to avoid adversely impacting online user requests. Scheduling the rebuilds to minimize the likelihood of data loss is the responsibility of the coordinator nodes.
Object availability is unaffected by failures thanks to online, real-time reconstruction of the objects:
When there are failures in a cell, some data blocks will become unavailable, and serving reads for the BLOBs it holds will require online reconstruction of them from companion data blocks and parity blocks. Backoff nodes are storage-less, CPU-heavy nodes that handle the online reconstruction of request BLOBs.
Some of f4’s details are also described in this Usenix video.
In 2015, Jeff Qin, Facebook’s capacity management engineer shared some more details about Facebook’s efforts to increase storage efficiency:
High storage efficiency means no UPS, no redundant power supplies, and no generators; just rack after rack after rack of storage. The facility was built from scratch in eighteen months, right down to the custom software it uses. It’s a lot quieter than a typical data center, as the service spins down unused drives to save energy.
Instagram is not what we would traditionally consider to be an object storage platform, but the requirements of the application are very similar: every photo (object) is uniquely addressable, those objects may have significant metadata, the service has a sophisticated permissions/access model that must be enforced per object and per bucket (user), the service must store a nearly unlimited number of objects, and every object must be accessible with a minimum of downtime and latency.
As noted below, the actual storage of the photos is outsourced to S3 (now, possibly to Haystack), but their database challenges are very similar to those faced in the metadata layer of object storage systems.
In 2011 they described that all photos were stored in S3, and the total amounted to “several terabytes” at the time.
In June 2012 Instagram went offline due to massive electrical storms on the US east coast, an event that Instagram co-founder Mike Krieger described as one of the five most important milestones in the service’s development.
In December 2012 they had to implement more sophisticated database sharding to accommodate “more than 25 photos and 90 likes every second.”
In 2013 they shared some tips about how they’re handling their scale in Postgres. Their tips focused on optimizing indexes, compaction, and backups to handle activity that had grown to “10,000 likes per second at peak.”
In 2014 they migrated their infrastructure from AWS to Facebook’s without mentioning S3. The article reveals that at the time of the migration they were running “many thousands of instances in EC2,” but it is not clear if they’re continuing to use S3, or if they’ve moved to Facebook’s Haystack object storage.
In 2015 they talked about scaling to multiple data centers in which we see Cassandra added alongside Postgres as part of their primary data store as they scaled to meet the demands of “400 million monthly active users with 40b photos and videos, serving over a million requests per second.”
A July 2017 presentation by Lisa Guo indicates Instagram is using Akamai as their CDN. Inspecting their website today reveals image URLs use the same pattern as those throughout Facebook (despite using the cdninstagram.com domain).This 2016 video from Guo is interesting as well.
This 2018 post claims Instagram now hosts 40 billion photos (growing 95 million per day) and is taking in 4.2 billion likes per day, but the company has been less forthcoming about the details of its infrastructure and how they’ve scaled to handle that volume of activity.
Manta
Manta is a replication-based object storage solution offered as part of Joyent’s Triton. Triton and Manta are available in public cloud, private cloud, and private region offerings.
Manta also offers integrated compute on data, called Manta Jobs, which compete in some ways against AWS’ S3 Select, Athena, and Lambda functions designed to interact with data on S3.
Unlike S3, Manta customers pay for each copy of the data stored. The default number of copies is 2, requiring 2× object size actual storage and fees.
Minio
Mino is an open source, S3-compatible object storage solution. It offers:
- Local persistence in a single instance or erasure coded across a cluster
- S3 API gateway access to third-party storage, including Manta
Minio has been rumored to be at the heart of DigitalOcean’s Spaces service (running a cluster per “Space,” DO’s term for “bucket”), but that is unconfirmed. The scale that Minio now supports is limited, but the implementation approach to create a storage pool per bucket has some similarities to AWS’ descriptions of S3 partitions (though a single bucket can have multiple partitions in S3).
S3
“S3” is actually a family of services from AWS to meet different storage needs:
- S3 Standard The basic service we used to call “S3,” but it now needs another label to differentiate it from others in the family.
- S3 Reduced Redundancy Storage Though AWS still publishes the docs for this service, they’ve removed it from their price list and it appears to be deprecated. The reasons for (non-)positioning are not clear, but it is worth noting that this is the only service in the S3 family that claims less durability that S3 Standard.
- S3 Infrequent Access (S3 IA) This storage tier is claimed to provide the same latency, durability, and availability as S3 Standard at a lower per unit cost for storage, but with increased fees for access and API operations.
- Glacier This storage tier is for data that is expected to be never accessed again and stored only for contingencies. It is implemented on tapes and latency can be minutes or hours.
Availability zones and facilities
These services are built atop AWS’ infrastructure, within its regions, availability zones, and facilities. However, S3 may be the only AWS service that utilizes the difference between “facilities” (physical data centers) and “availability zones” (logical constructs representing separate failure domains). A single AZ can be made up of up to eight facilities, but facilities in the same AZ might share failure domains with each other. A key point to take from this is that a region like us-east-1 might have up to six AZs, each with up to eight facilities.
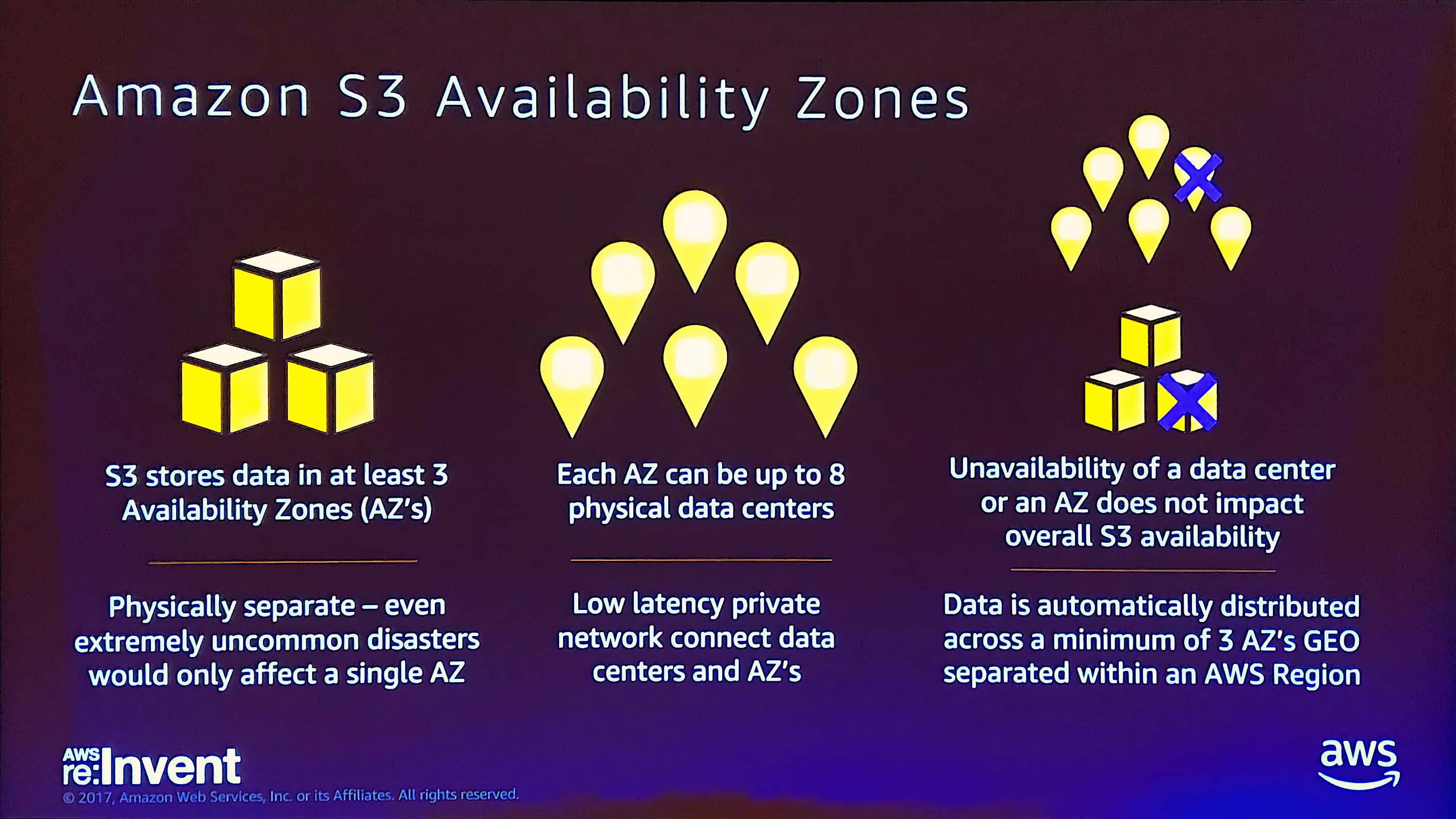
These details about the number of AZs and facilities are significant to S3’s availability and durability:
Amazon S3 is designed to sustain the concurrent loss of data in two facilities. […] Amazon S3 Standard and Standard - IA redundantly stores your objects on multiple devices across multiple facilities in an Amazon S3 Region. The service is designed to sustain concurrent device failures by quickly detecting and repairing any lost redundancy. When processing a request to store data, the service will redundantly store your object across multiple facilities before returning SUCCESS. Amazon S3 also regularly verifies the integrity of your data using checksums.
The slide above comes from an AWS re:Invent talk in 2017. Notable re:Invent talks include:
- AWS re:Invent 2017: Deep Dive on Amazon S3 & Amazon Glacier Infrastructure (STG301)
- AWS re:Invent 2017: Best Practices for Amazon S3, with Special Guest (STG302)
- AWS re:Invent 2017: Deep Dive on Data Archiving in Amazon S3 & Amazon Glacier (STG304)
- AWS re:Invent 2017: Deep Dive on Amazon S3 & Amazon Glacier Storage Management (STG311)
- AWS re:Invent 2016: Deep Dive on Amazon S3 (STG303)
- AWS re:Invent 2015: Amazon S3 Deep Dive and Best Practices (STG401)
- AWS re:Invent 2014 (PFC403) Maximizing Amazon S3 Performance
- AWS re:Invent 2013: Maximizing Amazon S3 Performance (STG304)
Edit after the fact: I estimate the size of S3 across all regions to be about 12-40 exabytes, and still growing fast (but not exponentially).
S3 Standard
Partitions
It’s not clear what the full scope of a partition includes, but they’re an implementation detail of the S3 metadata layer that AWS talks about publicly because of the relationship between partitions and performance. It has not been said outright, but it appears that every bucket starts with a a single partition, and then is divided into additional partitions as needed when it grows.
Each partition is said to support 100,000 requests per second. A partition can be as small as a single S3 object, or represent an entire bucket. It appears partitions are typically created in response to request volume, not object counts. Request volume includes both read and write. Single-object partitions are possible and were reported to be used for objects getting extraordinarily high numbers of read requests.
Partitioning appears to be as infinitely scalable as bucket and object counts, and is most useful as a mechanism to isolate performance problems as individual objects or buckets get “hot.” The automated tooling they have to repartition objects is critical to maintaining availability and performance for all customers. It’s not clear if they have tooling to collapse two or more partitions back into one, but they can definitely add partitions as needed.
Many people have long known that they should put short UUID-like strings at the front of their object keys so that objects could be better distributed among partitions. This is still true, but not everyone knows or follows this advice, so the S3 team has developed more sophisticated ways to partition objects and can now do this for single object keys.
Re-partitioning
AWS claims to automatically partition and re-partiton buckets to support high request rates:
If your request rate grows steadily, Amazon S3 automatically partitions your buckets as needed to support higher request rates. However, if you expect a rapid increase in the request rate for a bucket to more than 300 PUT/LIST/DELETE requests per second or more than 800 GET requests per second, we recommend that you open a support case to prepare for the workload and avoid any temporary limits on your request rate.
Request throttling
AWS’ guidelines identify two thresholds for request rates:
- 100 PUT/LIST/DELETE or 300 GET requests per second
- 300 PUT/LIST/DELETE or 800 GET requests per second
Those thresholds are per-bucket. Customers are recommended to follow a few best-practices guidelines, mostly related to key names, if they regularly or expect to cross the first threshold. Customers who anticipate crossing the second threshold are recommended to contact support to request rate limit increases and repartitioning.
AWS does not publish the threshold at which they will start throttling customers, but they do return 503 errors with a “SlowDown: Please reduce your request rate” message at some point (though I done tests that did over 2.3K PUTs and 6.1K GETS per second with 8KB objects without any pre-warming over a one minute period before I hit that limit).
Pay as you go
S3 users pay for bandwidth (though it’s free on its way in) and API requests (PUT, COPY, POST, LIST) on their data. Inventorying, storage class analysis, tags are all extra cost features, as are metrics and audit logging.
Cost optimization
The use of lifecycle policies to delete objects after a period of time, or move them to different storage classes (made easier with improved logging and reporting tools that AWS is providing) is increasingly commonplace.
S3 Infrequent Access
Those S3 IA provides lower cost storage than S3 Standard,the FAQ is very clear that durability, latency, and throughput are expected to be identical between them:
Amazon S3 Standard - Infrequent Access (Standard - IA) is an Amazon S3 storage class for data that is accessed less frequently, but requires rapid access when needed. Standard - IA offers the high durability, throughput, and low latency of Amazon S3 Standard, with a low per GB storage price and per GB retrieval fee. This combination of low cost and high performance make Standard - IA ideal for long-term storage, backups, and as a data store for disaster recovery. The Standard - IA storage class is set at the object level and can exist in the same bucket as Standard, allowing you to use lifecycle policies to automatically transition objects between storage classes without any application changes. […] S3 Standard - Infrequent Access provide the same performance as S3 Standard storage.
S3 IA is designed for slightly less availability than S3 Standard: it “has a thinner front end that provides nine one-hundredths of a percent less availability than S3 Standard,” but one is left to imagine the architecture that can match the performance of S3 Standard with a “thinner front end.” When I pressed a AWS re:Invent speaker on exactly what that meant, I was told that the difference in the SLAs between S3 Standard and IA had more to do with the newness of the service and market positioning than expected availability.
From the public materials, the most significant differences between S3 Standard and S3 IA are the fees for use and rules about use. S3 IA users must pay fees for the minimum age of objects (30 days), minimum object size (128KB), and higher fees for each request and per GB of transfer. Additionally, though it’s easy to move data from S3 Standard to IA, moving it back to S3 Standard requires more operations and bandwidth charges.
Glacier
This section is incomplete.
Depending on who you ask, Glacier is implemented on either optical media or tapes, with building-scale libraries and robots to shuttle media between the drives and the shelves.
They do periodic “fixity” checks (like ZFS consistency checks/scrubs) in which they may also write the objects to new media. This would be an opportunity to do garbage collection of deleted objects, but I don’t have specific information about that.
The claimed durability for Glacier is the same eleven nines as for S3, but a customer apparently worked with AWS to compare that to common backup practices and found the following:
- 99.999999999% = Glacier storage
- 99.999% = Two copies on two tapes in different buildings
- 99.99% = Two copies on different tapes in same building
RackSpace Cloud Files
RackSpace Cloud Files is the company’s OpenStack Swift-based object storage solution. It is not S3 compatible. It is notable for not being notable5, and one of the last product introductions from a company that has devolved to offering support for others’ clouds.
Wasabi
Wasabi is attacking S3 costs directly with its tagline: “Wasabi is just like Amazon S3. If Amazon S3 were 6x faster and 1/5th the price.” Their product offers a single tier of flat-rate storage priced at $.0039 per GB per month, with transfer priced at $.04/GB, and with no additional charges for PUTS or GETS, etc. Their service claims to be “bit compatible” with S3’s API.
S3 compatibility and ease of migration are keys to their strategy. They publish the status of their QA tests of third-party client tools, and a recent release included support for AWS’ IAM policies and STS tokens. Indeed, their docs claim that IAM policies can be copy-pasted from AWS with changes only to the identifiers. The only catch: their only region is us-east-1 (presumably in Virginia).
Yahoo’s internal object storage
Like Facebook, Yahoo’s object storage has evolved over time. In July 2009 the company introduced MObStore, its first-generation object storage solution. Yahoo’s acquisition of Flickr was a big driver for the development of object storage (Flickr hit four billion photos just a couple months after the MObStore announcement), but the company’s large number of media properties was also a factor.
A year later, in 2010, the company announced MObStore 2.0, which expanded replication across regions and added other features to improve usability. Just a couple months later, Flickr hit five billion photos.
In Spring 2015 the company announced it was replacing MObStore with Ceph. The primary driver was cost reductions. Though it’s only hinted at in the prior posts, MObStore achieves its availability goals through replication, but Yahoo’s vice president of architecture explains: “the biggest reason for moving to Ceph is that we just wanted lower storage costs.” Yahoo’s blog post highlights that by leading with some background on the scale of their storage problem and a brief education on the cost advantages of erasure coding:
Yahoo stores more than 250 Billion objects and half an exabyte of perpetually durable user content such as photos, videos, email, and blog posts. Object storage at Yahoo is growing at 20-25% annually. […]
The usable capacity of each cluster depends on the durability technique used. [With Ceph we use] erasure coding with each object broken down into eight data and three coding fragments. This mechanism, called 8/3 erasure coding, can tolerate up to three simultaneous server and/or disk failures with about 30% storage overhead for durability. This is much lower than the 200% overhead in case of [r=3] replication6.
The company claims to have implemented a number of optimizations to improve performance and better support the scale they’re operating at, but their optimizations appear to be within the constraints of Ceph’s architecture, rather than changes to it.
In a Quora answer from June 2015, a person claiming to be an engineer at Yahoo reiterated the company’s satisfaction with Ceph, but admitted there are two projects they’re working on:
- How to tune the performance for large number of small files.
- Low latency geo-replication.
The question of performance with large numbers of small files is one of particular interest for a number of use cases (it also appears to have been a factor for Facebook). Unfortunately, Yahoo entered a rapid decline post 2015 and does not appear to have published any updates to its object storage strategy since.
Also referenced: Franck Michel’s post that pokes at Flickr’s growth.
-
This can vary by installation and configuration. Erasure coding or replication of objects among multiple storage nodes significantly reduces the value of RAID in individual storage nodes. ↩︎
-
Resch expresses it differently than Reed-Solomon(n, k) terms. In Reed-Solomon(n, k) terms, “RAID 5 across 4 nodes” is n = 3, k = 1, and “10-of-15” is n = 10, k = 5. Though different from Reed-Solomon, Resch’s minimum-of-total terms may better emphasize the total number of nodes used, as well as the minimum number of nodes that must be available for the data to be available. ↩︎ ↩︎
-
It must be noted that total availability is the lesser of object availability, metadata availability, and the availability of other components in the request chain. ↩︎
-
The paper notes “over the course of a year, about 25% of the photos get deleted,” but “young photos are a lot more likely to be deleted.” That leaves me wishing they’d offered a graph of deletes by photo age. Is it a typical “big head and long tail” graph, or something more interesting, perhaps with a bump in the tail as their users age into adulthood and delete embarrassing pictures? ↩︎
-
Actually, Mosso CloudFiles was a reasonably well respected pre-2010 object storage solution, but the product stagnated after RackSpace acquired the company. The long road from Mosso CloudFiles to OpenStack Swift to RackSpace Cloud Files added little or no recognizable customer value or positively differentiated features. ↩︎
-
That’s “object size + 200%” or “3× object size” in total storage used. And, if the storage nodes use any RAID internally (as is common for systems that replicate whole objects), actual storage overhead could be higher yet. ↩︎